

You may have heard the term in passing before, the rumored-but-rarely-talked-about topic of the “deep web.” A web underneath the web, filled with petabytes of data and information that’s out of the reach of your standard Google, Bing, or Yahoo search bar.
But what is the deep web exactly? And what purpose does it serve for the greater research community as a whole? Read our guide to find out everything you need to know about the deep web, including what it means, where it lives, and how you can use it to your advantage.
The Deep Web: A Proper Definition
Google trawls the web for static webpage results using what’s known as a “spider-based crawler.” It returns them to you when you punch the right terms into the search bar. This only covers a very small portion of the actual information that’s available on the web.
The results you get back from a basic Google search are what’s known as the “Surface Web”. The Surface Web covers your basics: social media, news sites, shopping, blogs, etc.
Then there’s the Deep Web, which is not to be confused with the “Dark Web.” The Dark Web is a portion of the internet most often associated with privacy protection connection services like TOR and online drug marketplaces like the now-defunct Silk Road.
See also: How to access the deep web and darknet
The deep web contains a constantly updated torrent of raw, unchecked information, surging with complex technical terms and so many diagrams it’s enough to make Google’s Deep Dream AI blow a circuit board. These are documents that keep records for things like census data, NASA mission data, patents, and academic paper databases.
It’s estimated that the whole of the entire surface web only amounts to about 20 terabytes of information, or five percent of the information available for open search. On the other hand, the deep web occupies about 7.5 petabytes of information, or just around 95 percent of the total.
How to Search the Deep Web
Knowing where to look when diving into the deep end of the web is the first, and probably most important step you should take before starting anything else. The deep web is almost infinitely vast when it comes to the amount of information you can find. However, unlike what most people are used to when searching for something in Google, all of that data isn’t centralized in the same place.
This means for as many different subjects you can think of (finance, software, business, economics, academia, etc), there are an equal number of search engines designed to dive into the deep web archives of those particular subjects.
One issue that some researchers run into though is the problem of paywalls. There’s no getting around it: in order to run these websites/databases and keep the lights on, many of the sites mentioned below will keep their content hidden behind a paywall. It can cost upwards of $50 to read a single document. Alternatively, subscription plans can get you access to all content for a flat fee.
Avoiding paywalls
If paywalls are a problem for you, one tool we recommend checking out is the Google Chrome browser extension Unpaywall. Unpaywall automatically scours the web for a free version of any content you’re trying to access that says it’s behind a paywall. You may not always get back a free result for every paper you search, however it’s still nice to the know the option is there if you need it in a pinch.
Best deep web research tools
Below we’ve included a list of some of the services we think do the best job of cataloging all the information you might need during your next research project, making special note to highlight those that make it easier to search through than most.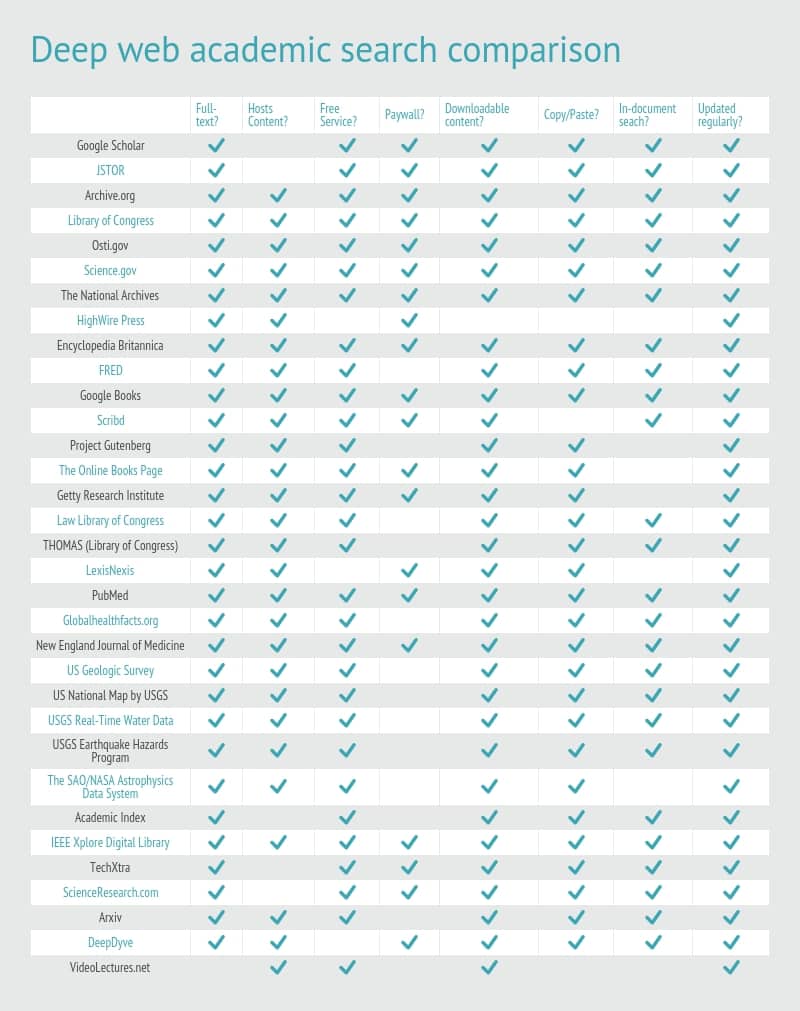
JSTOR — The first — and probably most obvious — addition to this list is the JSTOR database. Established in 1995, this treasure trove of research continues to be one of the first stops for any academic researcher on their way down the rabbit hole.
Offering full-text searches for over 2,000 individual journals and 15,000+ books, JSTOR is a must-have for anyone who prefers a more “one-stop shop” approach during their data deep dives.
JSTOR is also home to Artstor, which allows art historians and the like to search through 825,557 items drawn from 305 collections. Content is sourced from artists, photo archives, museums, libraries, scholars. It includes rare materials not available anywhere else.
A free JSTOR account will let you search across selected open access journals, ebooks, research reports, images, media, and special collections. The full range may be accessible through your public library or school. If not, an individual research subscription costs $19.50 a month/$199 per year, and will provide you with access to 85% of full journal runs on JSTOR and up to 120 PDF downloads.
Archive.org – A gigantic database of media that’s been entered into the public domain. Sound recordings, old videos, rare books, pretty much anything you might need to build your next great presentation at school, work, or both! It’s partnered with the Wayback Machine, which has over 280 billion webpages that have been indexed since nearly the inception of the internet itself. All content is free to access.
Library of Congress – Digitized archives of everything that’s entered the Library of Congress. Its collections contain more than 171 million books, recordings, periodicals, manuscripts, maps, images, music, and electronic resources. Online librarians and specialists are available to help locate material.
Osti.gov – Government research archives, complete with a history of all studies undertaken by the government. Your tax dollars paid for these, so why shouldn’t they belong to you? 100 percent searchable, and capable of returning results from within any document you’re trying to search for.
General
GPO’s Catalog of US Government Publications — A federal publications database that includes descriptive information for historical and current publications, with links to the full document when available.
The National Archives — National Archives’ research tools and online database. If there is anything you need to know about America’s history or the current state of the nation, this is the place. It’s a permanent store for the between 1% and 3% of government documents that are deemed important enough to be kept forever.
HighWire Press — Online catalog of the largest repository of free full-text and non-free text, peer-reviewed content, from over 1,000 different journals. It’s hit or miss as far as what’s behind a paywall and what isn’t. The only way to find out is to filter down your search terms to a point where you can see enough publications on both the paid and non-paid side of the aisle to decide whether or not you’ll need to pull out that wallet.
Encyclopedia Britannica — The original Google, now online with all the great pictures and text you still remember from the books! It’s seemingly random whether the information you want will be locked behind a paywall. Unlimited access costs $8.99 a month or $74.95 a year.
FRED — Up-to-date financial data covering 470,000 time series from 85 different resources, this database is provided free of charge thanks to the helping hands over at the Federal Reserve Bank of St. Louis. FRED links out to a number of other equally impressive resources for economic data. It should be the primary resource for anyone doing research in the fields of finance and economic theory in the US.
Books
Google Books – The most obvious choice. Though the other listings below are fine for what they do, but none can quite measure up to Google’s book-scanning prowess. Some books will have partial previews, others fully available, and even more still won’t let you see anything at all. All text is digitized (and searchable), but whether or not you’ll be able to read your results depends entirely on the state of the copyright license on that particular piece of text.
Scribd — This may not exactly fill the role of your ultimate academic research database, however the monthly subscription service is still a good way to stay up to date on any new articles that might be running in your favorite magazines or be able to search through books that just hit the shelves. The documents section allows users to upload pretty much anything with few restrictions, so it’s become a repository for many textbooks and other academic content.
Project Gutenberg — Provides 70,000 free e-books available online, and is part of the Archive.org searchable database. Browse bookshelves of related books or download catalogs.
The Online Books Page — A searchable database of over three million free online books. The site is hosted by the University of Pennsylvania Libraries.
Getty Research Institute – The Getty Research Institute library collections include over one million books, study photographs, periodicals and auction catalogs. There’s also a pretty deep collection of rare or unique materials that focus on art history and architecture.
Law and Politics
Law Library of Congress — Claims to be the largest collection of law books and other legal resources in the world. Its collection currently consists of more than one million titles, and over three million microform items. A searchable online catalog is available.
LexisNexis — Solid resource for any aspiring law student or practicing lawyer. Daily updated database of information, though it doesn’t come cheap. Prices for different services offered by LexisNexis will vary depending on the service and even what state you’re searching in, but expect to spend upwards of $125/month for services like Lexis Advance, which let you search through millions of court and legal documents submitted in actual cases from all around the United States. Before forking out any money, check whether your local library can help with access.
Medical and Health
Science.gov — Gateway to science info provided by US government agencies. Searches an aggregated database of 200 million different publications and journals. It’s recommended for anyone trying to do research on topics that are covered specifically under the “science” category.
PubMed — The U.S. National Library of Medicine contains over 16 million citations from MEDLINE and other life science journals reaching all the way back to the 1950’s. One of the first, and still one of the best medical databases available online today. Many articles are free to access.
New England Journal of Medicine — One of the leading medical journals with full text past issues available online. Be ready to pay for some content, but quite a bit is available for free as well. Subscriptions are available for $169 a year.
Science and Academic
Geography and Geology
US Geologic Survey – Packed with as many maps and images as you can stomach, covering many different aspects of the the US geological topography. Search through more than 160,000 publications authored by USGS scientists.
US National Map by USGS – The source for current geospatial data from the USGS. All maps provided are both interactively available on the web, as well as in their downloadable formats.
USGS Real-Time Water Data — A map of the United States showing real-time water quality data of the country’s rivers and reservoirs.
USGS Earthquake Hazards Program — Maps of the world showing real-time earthquake data. Has an interactive map that you can use to jump from location to location, fun for anyone who’s even got a passing level of interest in what’s really happening just under our feet.
Physics and Astronomy
The SAO/NASA Astrophysics Data System – A physics and astronomy data engine for academic papers. It’s one of the best ways to get your hands on the raw data pouring out from telescopes and physics experiments from all around the globe. Papers you want to read must be individually requested, which can be time consuming.
Academic Index – Splits into two different types of searches: the main search which basically returns more fine-tuned Google results, and the other that searches deep web academic troves. It aims to increase the visibility of academic information without the information overload of mainstream search engines.
Engineering and Technology
IEEE Xplore Digital Library — Contains over 1.4 million documents from the Institute of Electronics and Electrical Engineers. Searchable database of up-to-date materials regarding almost anything and everything to do with electrical engineering and technology as a whole.
National Technical Reports Library — Claims to have the largest collection of U.S. government-sponsored technical reports in existence. These are free to access.
Miscellaneous
Core — The world’s largest searchable database of open access research papers. Huge database of aggregated papers and research, all text-searchable. Should be your first stop for any early research that may not require as deep of a dive as somewhere else.
Arxiv — Cornell University repository. Access to 700,000+ technical papers on everything from quantitative biology to computer science. Appears to offer full text in several formats.
DeepDyve — A commercial trawler that has aggregated quite literally millions of articles across thousands of scientific journals. If you’re searching for anything in the way of STEM projects, this is a great place to start — though you’ll have to pay for the privilege. A monthly subscription costs $49.
Video Resources
VideoLectures.net – Really strong set of video lectures from high authority sources, nearly 26,000 lectures to choose from and over 30,000 informational videos in total.
TED — Diverse platform with more than 4,300 videos from industry speakers discussing topics in the fields of technology, design, science and global issues.
Image credit: “Library” from Pixabay licensed under CC BY 2.0






{kind=link}
Thank you for sharing this list of research services! It’s incredibly helpful to have resources that excel in cataloging the vast amount of information needed for research projects. I appreciate the emphasis on services that streamline the search process, as navigating through extensive databases can often be challenging. Having access to platforms that prioritize user-friendly search functionalities is invaluable for researchers. I look forward to exploring these services further and incorporating them into my future projects.
As a former medical librarian and now a professor at a major research university for more than a decade, I was glad to see the word “library” used so many times in this article; it is mysteriously missing from so many OTHER articles on this topic. A few clarifications are needed, though:
1. JSTOR has what is called a “moving wall” which means that depending on the content you are looking for, and the agreements publishers have reached with this vendor, you may be looking at articles no more recent than 3 years old. How much this matters depends on what content you are looking for. Read about the “moving wall” at: http://support.jstor.org/additional-resources-student-and-faculty/2015/7/21/what-the-what-is-a-moving-wall
2. Your comment (in the section on JSTOR) that “If you can’t afford that, many universities (more specifically, their professors) should have a subscription they’d be willing to let you use as long as you ask nicely enough!” struck me as rather bizarre. I really wouldn’t recommend writing a professor and asking them to hand over their passwords to their university computer systems. Even if we had time, we are unlikely to do this. Rather, seek out the closest public university to which your tax dollars guarantee you access, visit that university’s library and search for yourself using one of that library’s computers. It is not uncommon for public universities to have things called “community cards” which cost $25-30 a year and let you in to exploit those tax dollars to your heart’s content.
3. Finally, public libraries are able to help you obtain copies of articles, and the larger ones subscribe to some of the same databases of full-text content that the academic ones do.
Libraries are the best way to avoid paywalls I know.
Very good effort
The deep web is indeed a fascinating resource, one I have spent much time with. Since this article lists OSTI.gov, where I was Senior Consultant for Innovation for a decade, here are some refinements.
OSTI has ten different “collections” as they call them: https://www.osti.gov/home/catalogue-collections
However, the two biggest are actually portals performing federated search on other people’s collections, so they are not OSTI collections. These portals use a specific approach, where each distant collection is first searched using its own search engine, then the results are re-ranked collectively. No interoperability is needed among the collections, something the repository community might find useful. The technology is pretty amazing, yet inexpensive. It is provided by Deep Web Technologies — http://www.deepwebtech.com/. I recommend them highly.
The first of these federated portals is Science.gov — https://www.science.gov/, which the article incorrectly puts under Medical and Health. It actually searches over 60 federal document databases (plus 2200 websites) so the scope is all of funded science.
But the really big one (which I helped build) is WorldWideScience.org — https://worldwidescience.org/, which is not listed. OSTI organized and operates WWS.org. Here is the OSTI description: “OSTI hosts this international gateway to approximately 100 national science collections from more than 70 participating nations. WorldWideScience.org offers simultaneous, real-time searching of the most current information from around the world in fields such as energy, medicine, agriculture, environment, and basic sciences. Multilingual translation capabilities are available for ten languages: Arabic, Chinese, English, French, German, Japanese, Korean, Portuguese, Russian, and Spanish. Content includes text-based and multimedia information, as well as research data.” Science.gov is just one of the 100 or so federated collections, so WWS.org is a monster second order federation.
I am proud to say that the multilingual translation feature, built and operated by Microsoft, was my idea. A query entered in a given user language is translated into the language needed to search each national collection, many of which are not in English. The search results are then all translated back into the user’s language. Of course machine translation is limited and the results can be pretty rough but it is still a great step forward. I can search Chinese, Arabic, Russian, German, Japanese, …. language science collections simultaneously and read all the results. Woohoo!
David Wojick
http://insidepublicaccess.com/
One option for searching some of the databases like JSTOR, PubMed, and others is to run a site-limited query in Google that returns only results from the database to which the query is limited. For example a JSTOR-limited search: “marshall plan” OR “european recovery program” AND U.S. AND strategy AND site:jstor.org. The advanced search syntaxes work; for example a title search: intitle:vaccines AND children AND site:medlineplus.gov.
Thank you for this fascinating trove of information sources.
mario